Software Marketing, enter a world of countless project requests, numerous stakeholders, limited resources and rapidly changing market conditions.
Sound familar? In fact, marketers face a lot of the same challenges as development teams, and Agile can be a powerful way to alleviate those common issues and intelligently plan our work.
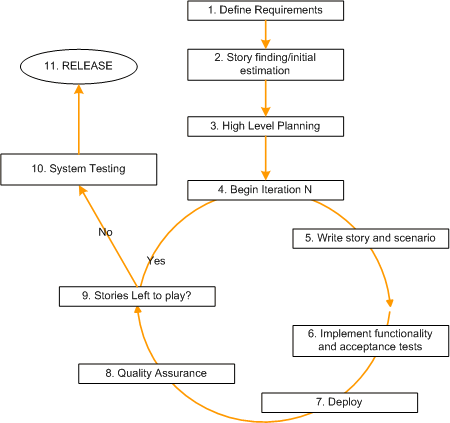
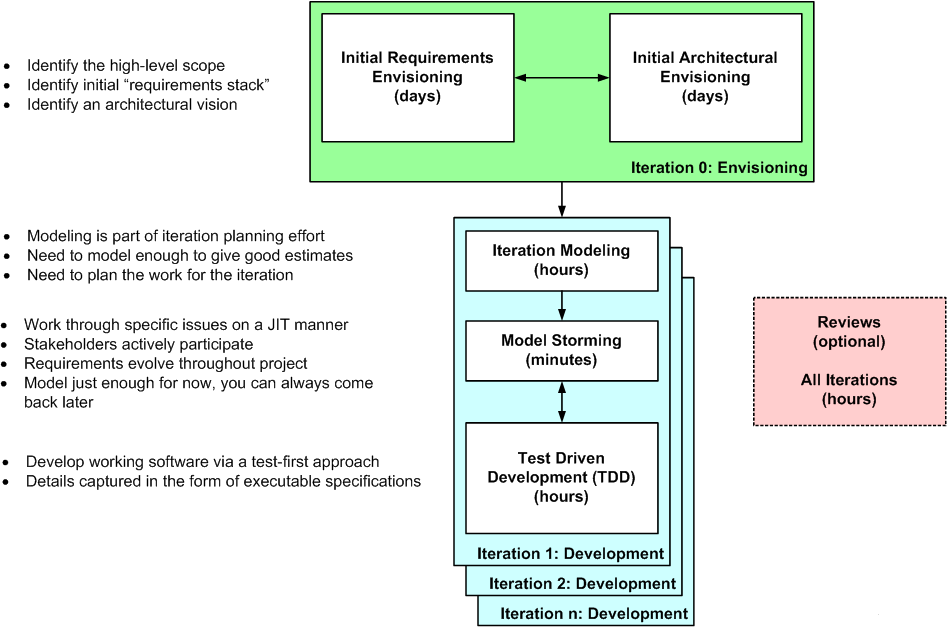
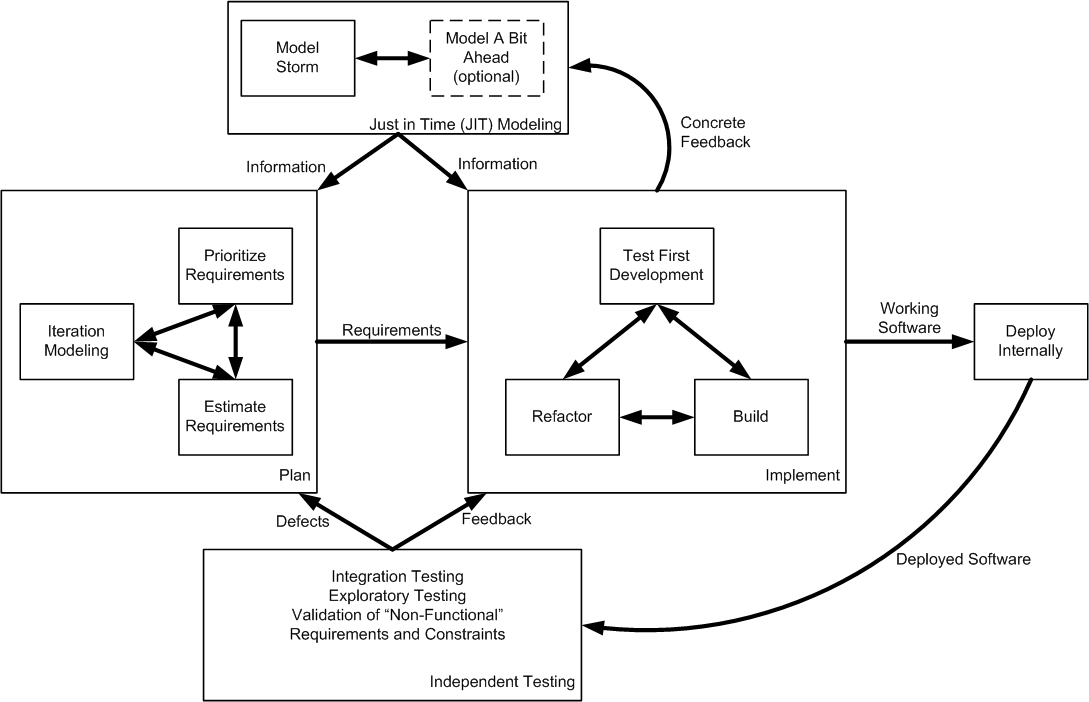
10 Steps to successful Marketing using Agile and Lean Practices:In steps 1-5, Explain how marketing team conducts our version of release planning.
In step 6-10, Explain how we run our iterations to meet those commitments. Our planning processes continue to evolve, through this method has worked for a while now.
PART 1
STEP 1: We recognize that Marketing has challenges that are different from development.
- There is no unique product owner: for example if we chose Sales, when we would always rank lead generation over branding, customer programs or analyst relations, and that could ultimately hurt our company. Therefore we have to use some best-guessing to prioritize our backlog and determine what is most important.
- We face hard event deadlines set far into the future. Sometimes we have no choice but to commit to an event or sign a contract months ahead of time.
- Each team member has unique expertise, i.e. writing, event planning, PHP development and so forth. So one shared backlog is inefficient.
Now that we've reviewed the challenges,w e give ourselves permission to do what we need to do, have patience and adjust anything that isn't working for us.
STEP 2: Conduct an ORID to learn from the past:
Before planning for the next quarter, we hold a retrospective in the form of an ORID, “a means to analyze facts and feelings, to ask about implications and to make decisions intelligently”, a process created by the Institute of Cultural Affairs. We gather as a team to share
- Observations (O) – What do we know?
- Reflections (R) – How do we feel about this?
- Interpretations (I) – What does it mean for the organization?
- Decisions (D) – What are we going to do?
This strategic overview helps set context for us to prioritize our focus for next quarter.
STEP 3: Align ORID decision with company strategy:
We conduct quarterly (as per company strategy) and annual planning using the Plan Do Check Adjust methodology as explained in Getting the Right Things Done. As we look at the overall company direction and goals, we keep these in mind as we hold planning at our own level. Ideally, our major commitments support and align with company strategy. This also helps inform our “stop doing” list.
STEP 4: Poll our stack holders:
As part of determining quarterly commitments, we poll our major stakeholders for their top requests. We use a Google survey to rank these requests by importance, size each request and bring these epics into our release planning meeting, to be included as part of our ranked backlog.
STEP 5: Conduct release planning to prioritize and agree on quarterly commitment:
Now that we have all of our inputs, we hold our quarterly Release Planning session. We write each epic on a sticky note and look at all of the possible work we could do this quarter. Then, we evaluate epics based on importance taking company goals, stakeholder wishes, market realities like conferences and our own passions into consideration. We decide what we can realistically commit to, and agree as a team. We keep in mind that making and meeting commitments is a huge deal, and we try really hard not to over-commit.
PART 2
STEP 6: Create a task board:
Since our marketing team is mostly co-located, we pin up several large sheets of paper to use as a task board. This is where we review our commitments on a daily basis as a sanity check that our stories are prioritized correctly and that we are tackling the right work as the quarter progresses.
As a team, we write our quarterly commitments on the task board with the definition of done assigned to each one. We also include our “foundational” work – recurring work like website updates, online ad campaigns, field events, press releases and other important work that we need time to do.
We break into smaller project teams that do share a backlog, we often use AgileZen to manage this work.
STEP 7: Hold Iteration planning every two week:
Every 2 weeks, we hold an Iteration Planning meeting. Each team member has her own sticky note color, creates stories on those notes and manages her own prioritized backlog using T-shirt sizing to roughly estimate each story. In this hour-long meeting, we begin by expressing appreciation for team members who gave exceptional assistance. Then we hold a brief retrospective on what worked and what should change for the next iteration. Finally, we each read out our prioritized stories for the iteration, putting them on the task board’s backlog. This gives everyone visibility to what’s happening, identifies if someone is over-committed and lets the team swarm any epics with looming deadlines
STEP 8: Conduct a daily Stand up meeting:
At the same time each day, we hold a stand-up meeting (with a consistent conference call #) that is at most 10-15 minutes long. We form a semi-circle in front of our task board and share no more than 2 cross-cutting significant actions or take-aways from the day before, no more than 2 that we are planning to accomplish that day, and whether our work is blocked by any issues beyond our control. As we start working on stories throughout the iteration, we move them from the backlog into their section of the task board to show what we are working on. When the story is complete, then we move it to a place on the task board labeled “Done”. Once the commitment’s Definition of Done is met, we check off that commitment and feel good about completing it.
STEP 9: Be patience as things change:
It would be lovely if nothing changed during the iteration, but that just doesn’t happen. The goal is ultimately to respond to change rather than cling to an outdated plan. As new opportunities arise, new time-sensitive information appears and new requests are made, so our iteration work changes and that’s ok. We try to just document what we’re working on and create new stories so that we can make intelligent prioritization decisions during the course of the iteration.
STEP 10: Retrospect, Inspect and Adapt:
As we keep running our iterations and fulfilling our commitments, we are always looking for ways to improve them. Ultimately, we’re using Agile to improve the quality of our work life by using objective, smart ways of planning how we spend our time. And we’re learning a lot from the journey.