This error completely stumped me a couple of weeks ago. Apparently someone was adjusting the Apache configuration, then they checked their syntax and attempted to restart Apache. It went down without a problem, but it refused to start properly, and didn't bind to any ports.
Within the Apache error logs, this message appeared over and over:
[emerg] (28)No space left on device: Couldn't create accept lock
Apache is basically saying "I want to start, but I need to write some things down before I can start, and I have nowhere to write them!" If this happens to you, check these items in order:
1. Check your disk space
This comes first because it's the easiest to check, and sometimes the quickest to fix. If you're out of disk space, then you need to fix that problem.
2. Review filesystem quotasIf your filesystem uses quotas, you might be reaching a quota limit rather than a disk space limit. Use repquota / to review your quotas on the root partition. If you're at the limit, raise your quota or clear up some disk space. Apache logs are usually the culprit in these situations.
3. Clear out your active semaphoresSemaphores? What the heck is a semaphore? Well, it's actually an apparatus for conveying information by means of visual signals. But, when it comes to programming, semaphores are used for communicating between the active processes of a certain application. In the case of Apache, they're used to communicate between the parent and child processes. If Apache can't write these things down, then it can't communicate properly with all of the processes it starts.
I'd assume if you're reading this article, Apache has stopped running. Run this command as root:
# ipcs -s
-----------------------------
# ipcs
# ipcrm -s sem_id
# ipcrm -m mem_id
-----------------------------
If you see a list of semaphores, Apache has not cleaned up after itself, and some semaphores are stuck. Clear them out with this command:
# for i in `ipcs -s | awk '/httpd/ {print $2}'`; do (ipcrm -s $i); done
Now, in almost all cases, Apache should start properly. If it doesn't, you may just be completely out of available semaphores. You may want to increase your available semaphores, and you'll need to tickle your kernel to do so. Add this to /etc/sysctl.conf:
kernel.msgmni = 1024
kernel.sem = 250 256000 32 1024
And then run sysctl -p to pick up the new changes.
Monday, January 30, 2012
Sunday, January 29, 2012
What is 'No SQL' ?
NoSQL is a term used to refer to a class of database systems that differ from the traditional relational database management systems (RDBMS) in many ways. RDBMSs are accessed using SQL. Hence the term NoSQL implies not accessed by SQL. More specifically not RDBMS or more accurately not relational.
Some key characteristics of NqSQL databases are :
Theoretically, relational databases comply with Codds 12 rules of relational model. More simply, in RDBMS, a table is relation and database has a set of such relations. A table has rows and columns. Each table has contraints and the database enforces the constraints to ensure the integrity of data.Each row in a table is identified by a primary key and tables are related using foreign keys. You eliminate duplicate data during the process of normalization, by moving columns into separate tables but keeping the relation using foreign keys. To get data out of multiple tables requires joining the tables using the foreign keys. This relational model has been useful in modeling most real world problems and is in widespread use for the last 20 years.
In addition, RDBMS vendors have gone to great lengths to ensure that RDBMSs do a great job in maintaining ACID (actomic, consistent, integrity, durable) transactional properties for the data stored. Recovery is supported from unexpected failures. This has lead to relational databases becoming the de facto standard for storing enterprise data.
If RDBMSs are so good, Why does any one need NoSQL databases ?Even the largest enterprises have users only in the order of 1000s and data requirements in the order of few terra bytes. But when your application is on the internet, where you are dealing with millions of users and data in the order of petabytes, things start to slow down with a RDBMS. The basic operations with any database are read and write. Reads can be scaled by replicating data to multiple machines and load balancing read requests. However this does not work for writes because data consistency needs to be maintained. Writes can be scaled only by partitioning the data. But this affects read as distributed joins can be slow and hard to implement. Additionally, to maintain ACID properties, databases need to lock data at the cost of performance.
The Googles, facebooks , Twitters have found that relaxing the constraints of RDBMSs and distributing data gives them better performance for usecases that involve
There are a few different types.
1. Key Value Stores
They allow clients to read and write values using a key. Amazon's Dynamo is an example of a key value store.
get(key) returns an object or list of objects
put(key,object) store the object as a blob
Dynamo use hashing to partition data across hosts that store the data. To ensure high availability, each write is replicated across several hosts. Hosts are equal and there is no master. The advantage of Dynamo is that the key value model is simple and it is highly available for writes.
2. Document stores
The key value pairs that make up the data are encapsulated as a document. Apache CouchDB is an example of a document store. In CouchDB , documents have fields. Each field has a key and value. A document could be
--------------------------------------------------------
1 "firstname " : " John ",
2 "lastname " : "Doe" ,
3 "street " : "1 main st",
4 "city " : "New york"
----------------------------------------------------------
In CouchDB, distribution and replication is peer to peer. Client interface is RESTful HTTP, that integrated well with existing HTTP loadbalancing solutions.
3. Column based storesRead and write is done using columns rather than rows. The best known examples are Google's BigTable and the likes of HBase and Cassandra that were inspired by BigTable. The BigTable paper says that BigTable is a sparse, distributed, persistent, multidimensional sorted Map. While that sentence seems complicated, reading each word individually gives clarity.
-----------------------------------------------------------------------------------------------------
{
row1:{
user:{
name: john
id : 123
},
post: {
title:This is a post
text : xyxyxyxx
}
}
row2:{
user:{
name: joe
id : 124
},
post: {
title:This is a post
text : xyxyxyxx
}
}
row3:{
user:{
name: jill
id : 125
},
post: {
title:This is a post
text : xyxyxyxx
}
}
}
-----------------------------------------------------------------------------------------------
The outermost keys row1,row2, row3 are analogues to rows. user and post are what are called column families. The column family user has columns name and id. post has columns title and text.
Columnfamily:column is how you refer to a column. For eg user:id or post:text. In Hbase, when you create the table, the column families need to be specified. But columns can be added on the fly. HBase provides high availability and scalability using a master slave architecture.
Do I needs a NoSQL store ?
You do not need a NoSQL store if:
Some key characteristics of NqSQL databases are :
- They are distributed, can scale horizontally and can handle data volumes of the order of several terrabytes or petabytes, with low latency.
- They have less rigid schemas than a traditional RDBMS.
- They have weaker transactional guarantees.
- As suggested by the name, these databases do not support SQL.
- Many NoSQL databases model data as row with column families, key value pairs or documents
Theoretically, relational databases comply with Codds 12 rules of relational model. More simply, in RDBMS, a table is relation and database has a set of such relations. A table has rows and columns. Each table has contraints and the database enforces the constraints to ensure the integrity of data.Each row in a table is identified by a primary key and tables are related using foreign keys. You eliminate duplicate data during the process of normalization, by moving columns into separate tables but keeping the relation using foreign keys. To get data out of multiple tables requires joining the tables using the foreign keys. This relational model has been useful in modeling most real world problems and is in widespread use for the last 20 years.
In addition, RDBMS vendors have gone to great lengths to ensure that RDBMSs do a great job in maintaining ACID (actomic, consistent, integrity, durable) transactional properties for the data stored. Recovery is supported from unexpected failures. This has lead to relational databases becoming the de facto standard for storing enterprise data.
If RDBMSs are so good, Why does any one need NoSQL databases ?Even the largest enterprises have users only in the order of 1000s and data requirements in the order of few terra bytes. But when your application is on the internet, where you are dealing with millions of users and data in the order of petabytes, things start to slow down with a RDBMS. The basic operations with any database are read and write. Reads can be scaled by replicating data to multiple machines and load balancing read requests. However this does not work for writes because data consistency needs to be maintained. Writes can be scaled only by partitioning the data. But this affects read as distributed joins can be slow and hard to implement. Additionally, to maintain ACID properties, databases need to lock data at the cost of performance.
The Googles, facebooks , Twitters have found that relaxing the constraints of RDBMSs and distributing data gives them better performance for usecases that involve
- Large datasets of the order of petabytes. Typically this needs to stored using multiple machines.
- The application does a lot of writes.
- Reads require low latency.
- Data is semi structured.
- You need to be able to scale without hitting a bottleneck.
- Application knows what it is looking for. Adhoc queries are not required.
There are a few different types.
1. Key Value Stores
They allow clients to read and write values using a key. Amazon's Dynamo is an example of a key value store.
get(key) returns an object or list of objects
put(key,object) store the object as a blob
Dynamo use hashing to partition data across hosts that store the data. To ensure high availability, each write is replicated across several hosts. Hosts are equal and there is no master. The advantage of Dynamo is that the key value model is simple and it is highly available for writes.
2. Document stores
The key value pairs that make up the data are encapsulated as a document. Apache CouchDB is an example of a document store. In CouchDB , documents have fields. Each field has a key and value. A document could be
--------------------------------------------------------
1 "firstname " : " John ",
2 "lastname " : "Doe" ,
3 "street " : "1 main st",
4 "city " : "New york"
----------------------------------------------------------
In CouchDB, distribution and replication is peer to peer. Client interface is RESTful HTTP, that integrated well with existing HTTP loadbalancing solutions.
3. Column based storesRead and write is done using columns rather than rows. The best known examples are Google's BigTable and the likes of HBase and Cassandra that were inspired by BigTable. The BigTable paper says that BigTable is a sparse, distributed, persistent, multidimensional sorted Map. While that sentence seems complicated, reading each word individually gives clarity.
- sparse - some cells can be empty
- distributed - data is partitioned across many hosts
- persistent - stored to disk
- multidimensional - more than 1 dimension
- Map - key and value
- sorted - maps are generally not sorted but this one is
-----------------------------------------------------------------------------------------------------
{
row1:{
user:{
name: john
id : 123
},
post: {
title:This is a post
text : xyxyxyxx
}
}
row2:{
user:{
name: joe
id : 124
},
post: {
title:This is a post
text : xyxyxyxx
}
}
row3:{
user:{
name: jill
id : 125
},
post: {
title:This is a post
text : xyxyxyxx
}
}
}
-----------------------------------------------------------------------------------------------
The outermost keys row1,row2, row3 are analogues to rows. user and post are what are called column families. The column family user has columns name and id. post has columns title and text.
Columnfamily:column is how you refer to a column. For eg user:id or post:text. In Hbase, when you create the table, the column families need to be specified. But columns can be added on the fly. HBase provides high availability and scalability using a master slave architecture.
Do I needs a NoSQL store ?
You do not need a NoSQL store if:
- All your data fits into 1 machine and does not need to be partitioned.
- You are doing OLTP which required the ACID transaction properties and data consistency that RDBMSs are good at.
- You need ad hoc querying using a language like SQL.
- You have complicated relationships between the entities in your applications.
- Decoupling data from application is important to you.
- Your data has grown so large that it can no longer be handled without partitioning.
- Your RDBMS can no longer handle the load.
- You need very high write performance and low latency reads.
- Your data is not very structured.
- You can have no single point of failure.
- You can tolerate some data inconsistency.
Saturday, January 28, 2012
Installing Dansguardian on LinuxMCE
DansGuardian is an award winning Open Source web content filter which currently runs on Linux, FreeBSD, OpenBSD, NetBSD, Mac OS X, HP-UX, and Solaris. It filters the actual content of pages based on many methods including phrase matching, PICS filtering and URL filtering. It does not purely filter based on a banned list of sites like lesser totally commercial filters.
DansGuardian is designed to be completely flexible and allows you to tailor the filtering to your exact needs. It can be as draconian or as unobstructive as you want. The default settings are geared towards what a primary school might want but DansGuardian puts you in control of what you want to block.
DansGuardian is a true web content filter. We will see how to configure DansGuardian on Ubuntu Linux along with LinuxMCE.
Installing packages
tinyproxy
apt-get install tinyproxy
shorewall
apt-get install shorewall
dansguardian
apt-get install dansguardian
dhcp
apt-get install dhcp3-server
dns server
apt-get install dnsmasq
Dansguardian Web Log Viewer
apt-get install dglog
Installing webmin and dansguardian webmin module
First you need to install the additional packages:
sudo aptitude install perl libnet-ssleay-perl openssl libauthen-pam-perl libpam-runtime libio-pty-perl libmd5-perl
Download and install webmin package:
wget http://prdownloads.sourceforge.net/webadmin/webmin_1.480_all.deb
sudo dpkg -i webmin_1.480_all.deb
Configure PackagesTinyproxy
vi /etc/tinyproxy/tinyproxy.conf
Make the following changes
1. User root
2. Group root
3. Allow 192.168.80.0/25
Dansguardian
vi /etc/dansguardian/dansguardian.conf
Make the following changes:
1. Delete UNCONFIGURED line
2. filterport = 8081
3. proxyip = 192.168.80.1
4. proxyport = 8888
5. usernameidmethodproxyauth = off
Shorewall:
Make the following changes:
copy configuration files (take backup of existing files):
cp /usr/share/doc/shorewall-common/default-config/* /etc/shorewall/
set "shorewall" auto start at boot time:
vi /etc/default/shorewall
startup = 1
"zones" tells the firewall to zone each name for the rest configuration file e.g. loc, net:
vi /etc/shorewall/zones
1. #ZONES TYPE OPTION IN OUT
2. #OPTIONS OPTIONS
3. fw firewall
4. net ipv4
5. loc ipv4
6. #Last Line - ADD ENTRIES ABOVE THIS ONE - DO NOT REMOVE
"interfaces" tells the firewall which is internal and external interfaces:
vi /etc/shorewall/interfaces
1. #ZONE INTERFACE BROADCAST OPTIONS
2. #Note assuming "eth1"- is internal ip & "eth0"- is external ip
3. net eth0 detect dhcp,tcpflags
4. loc eth1 detect dhcp
5. #LAST LINE --ADD YOUR ENTRIES ABOVE THIS ONE - DO NOT REMOVE
"masq" tells the firewall that internal network(eth1)is connected through external network(eth0):
vi /etc/shorewall/masq
1. #INTERFACE SUBNET ADDRESS PROTO PORT(S) IPSEC
2. eth0 eth1
3. #LAST LINE --ADD YOUR ENTRIES ABOVE THIS ONE - DO NOT REMOVE
"policy" tells the firewall that how should handle the requests:
vi /etc/shorewall/policy
1. loc all ACCEPT
2. net all DROP
3. fw all ACCEPT
4. all all REJECT
"shorewall.conf" we will configure ip_forwarding:
vi /etc/shorewall/shorewall.conf
1. IP_FORWARDING=On
"rules" allows to set firewall rules:
vi /etc/shorewall/rules 1. SECTION NEW
2. ACCEPT net fw tcp 80
3. REDIRECT loc 8081 tcp www
4. ACCEPT loc fw tcp 22
5. ACCEPT net fw icmp
6. ACCEPT loc loc icmp
7. #LAST LINE --ADD YOUR ENTRIES ABOVE THIS ONE - DO NOT REMOVE
# check shorewall working or not properly:
shorewall check
Restart Applications
/etc/init.d/dnsmasq restart
/etc/init.d/tinyproxy restart
/etc/init.d/shorewall restart
/etc/init.d/dansguardian restart
Troubleshooting:
1. Still not working restart the system once
2. Check all service started are not "ps -ef | grep" service - apache2, dnsmasq, tinyproxy, shorewall, dansguardian, and dhcpd. If any of the service is not starting, start the service sh /etc/init.d. start. Check especially dnsmasq and shorewall services.
DHCP Server:
Note: you need not to make any changes if you are working on single system or dhcp is already running on your local network interface(any changes dhcpd.conf or interfaces respective files)
vi /etc/default/dhcp3-server
1. INTERFACE="eth1"
vi /etc/dhcp3/dhcpd.conf
1. #change the subnet, netmask, range, dns, router as per your settings
2. default-leasetime=86400
3. max-leasetime=60480
4. subnet 192.168.0.0 netmask 255.255.255.0{
5. range 192.168.0.2 192.168.1.99;
6. option domain-name-server 192.168.80.1;
7. option routers 192.168.80.2;
8. }
set static ip address:
vi /etc/network/interfaces
1. auto lo
2. iface lo inet loopback
3. auto eth0
4. iface eth0 inet dhcp
5. auto eth1
6. iface eth1 inet static
7. address 192.168.80.1
8. netmask 255.255.255.0
#restart dhcp
/etc/init.d/dhcpd restart
Adding BlackList
A BlackList is a precompiled list of sites that are deemed potentially worrisome.
cd /etc/dansguardian
wget http://urlblacklist.com/downloads/OriginalUpdateBL
vi OriginalUpdateBL
1. modify line 68 by switching the listed URL with the following:
2. http://urlblacklist.com/cgi-bin/commercialdownload.pl?type=download&file=bigblacklist
chmod 777 /etc/dansguardian/OriginalUpdateBL
/etc/dansguardian/OriginalUpdateBL
when script is finished if you see any errors.
/etc/init.d/dansguardian restart
if the above script is not creating blacklists directory and creating blacklists file then follow the following:
cd /etc/dansguardian
wget http://urlblacklist.com/cgi-bin/commercialdownload.pl?type=download&file=bigblacklist
tar -xvf bigblacklist.tar.gz
chown -R root:root blacklists
chmod -R 755 blacklists
Webmin and Dansguardian webmin configuration
Login into Webmin(open your web browser and enter the following):
https://192.168.80.1:10000/
Install and configure the Dansguardian Webmin module:
1.Open browser & login as madmin(sudo user) https://192.168.80.1:10000
2.Go to Webmin > Webmin Configuration > Webmin Modules
Select "From ftp or http URL" and paste the link below into the dialog box and click Install Module.
(http://downloads.sourceforge.net/project/dgwebminmodule/dgwebmin-devel/0.7.0beta1b/dgwebmin-0.7.0beta1b.wbm?use_mirror=voxel)
Observe: The following modules have been successfully installed and added to your access control list :
DansGuardian Web Content Filter in /usr/share/webmin/dansguardian (4612 kB) under category Servers
Trouble shooting:
The first time you try to run the dg module, you'll get errors such as:
Warning - DansGuardian binary file not found, maybe you need to update your module config (especially the directory paths). (Expected location: /sbin/dansguardian)
Solution:The problem is that the we are using different directory locations for many of the files. So, look at the Configurable options for DansGuardian Web Content Filter (in the upper left corner of the dg page) - and nearly every path needs to be changed.
For instance, our binary is in /usr/sbin/dansguardian instead of /sbin/dansguardian, so change that.
Confirm the locations for the rest of the files by running
find / -name dansguardian
results may show:
/usr/share/webmin/dansguardian
/usr/share/lintian/overrides/dansguardian
/usr/share/doc/dansguardian
/usr/share/dansguardian
/usr/sbin/dansguardian
/var/log/dansguardian
/etc/webmin/dansguardian
/etc/init.d/dansguardian
/etc/logrotate.d/dansguardian
/etc/dansguardian
When you've finished replacing all of the locations, hit save on the config page and then "stop & restart DG" on the top right of the main DG page.
Then it should work! If not, check your syslog for errors. You should be able to check the status of DG, review logs with a good viewer, and view and edit many of the detailed configurations.
DansGuardian is designed to be completely flexible and allows you to tailor the filtering to your exact needs. It can be as draconian or as unobstructive as you want. The default settings are geared towards what a primary school might want but DansGuardian puts you in control of what you want to block.
DansGuardian is a true web content filter. We will see how to configure DansGuardian on Ubuntu Linux along with LinuxMCE.
Installing packages
tinyproxy
apt-get install tinyproxy
shorewall
apt-get install shorewall
dansguardian
apt-get install dansguardian
dhcp
apt-get install dhcp3-server
dns server
apt-get install dnsmasq
Dansguardian Web Log Viewer
apt-get install dglog
Installing webmin and dansguardian webmin module
First you need to install the additional packages:
sudo aptitude install perl libnet-ssleay-perl openssl libauthen-pam-perl libpam-runtime libio-pty-perl libmd5-perl
Download and install webmin package:
wget http://prdownloads.sourceforge.net/webadmin/webmin_1.480_all.deb
sudo dpkg -i webmin_1.480_all.deb
Configure PackagesTinyproxy
vi /etc/tinyproxy/tinyproxy.conf
Make the following changes
1. User root
2. Group root
3. Allow 192.168.80.0/25
Dansguardian
vi /etc/dansguardian/dansguardian.conf
Make the following changes:
1. Delete UNCONFIGURED line
2. filterport = 8081
3. proxyip = 192.168.80.1
4. proxyport = 8888
5. usernameidmethodproxyauth = off
Shorewall:
Make the following changes:
copy configuration files (take backup of existing files):
cp /usr/share/doc/shorewall-common/default-config/* /etc/shorewall/
set "shorewall" auto start at boot time:
vi /etc/default/shorewall
startup = 1
"zones" tells the firewall to zone each name for the rest configuration file e.g. loc, net:
vi /etc/shorewall/zones
1. #ZONES TYPE OPTION IN OUT
2. #OPTIONS OPTIONS
3. fw firewall
4. net ipv4
5. loc ipv4
6. #Last Line - ADD ENTRIES ABOVE THIS ONE - DO NOT REMOVE
"interfaces" tells the firewall which is internal and external interfaces:
vi /etc/shorewall/interfaces
1. #ZONE INTERFACE BROADCAST OPTIONS
2. #Note assuming "eth1"- is internal ip & "eth0"- is external ip
3. net eth0 detect dhcp,tcpflags
4. loc eth1 detect dhcp
5. #LAST LINE --ADD YOUR ENTRIES ABOVE THIS ONE - DO NOT REMOVE
"masq" tells the firewall that internal network(eth1)is connected through external network(eth0):
vi /etc/shorewall/masq
1. #INTERFACE SUBNET ADDRESS PROTO PORT(S) IPSEC
2. eth0 eth1
3. #LAST LINE --ADD YOUR ENTRIES ABOVE THIS ONE - DO NOT REMOVE
"policy" tells the firewall that how should handle the requests:
vi /etc/shorewall/policy
1. loc all ACCEPT
2. net all DROP
3. fw all ACCEPT
4. all all REJECT
"shorewall.conf" we will configure ip_forwarding:
vi /etc/shorewall/shorewall.conf
1. IP_FORWARDING=On
"rules" allows to set firewall rules:
vi /etc/shorewall/rules 1. SECTION NEW
2. ACCEPT net fw tcp 80
3. REDIRECT loc 8081 tcp www
4. ACCEPT loc fw tcp 22
5. ACCEPT net fw icmp
6. ACCEPT loc loc icmp
7. #LAST LINE --ADD YOUR ENTRIES ABOVE THIS ONE - DO NOT REMOVE
# check shorewall working or not properly:
shorewall check
Restart Applications
/etc/init.d/dnsmasq restart
/etc/init.d/tinyproxy restart
/etc/init.d/shorewall restart
/etc/init.d/dansguardian restart
Troubleshooting:
1. Still not working restart the system once
2. Check all service started are not "ps -ef | grep
DHCP Server:
Note: you need not to make any changes if you are working on single system or dhcp is already running on your local network interface(any changes dhcpd.conf or interfaces respective files)
vi /etc/default/dhcp3-server
1. INTERFACE="eth1"
vi /etc/dhcp3/dhcpd.conf
1. #change the subnet, netmask, range, dns, router as per your settings
2. default-leasetime=86400
3. max-leasetime=60480
4. subnet 192.168.0.0 netmask 255.255.255.0{
5. range 192.168.0.2 192.168.1.99;
6. option domain-name-server 192.168.80.1;
7. option routers 192.168.80.2;
8. }
set static ip address:
vi /etc/network/interfaces
1. auto lo
2. iface lo inet loopback
3. auto eth0
4. iface eth0 inet dhcp
5. auto eth1
6. iface eth1 inet static
7. address 192.168.80.1
8. netmask 255.255.255.0
#restart dhcp
/etc/init.d/dhcpd restart
Adding BlackList
A BlackList is a precompiled list of sites that are deemed potentially worrisome.
cd /etc/dansguardian
wget http://urlblacklist.com/downloads/OriginalUpdateBL
vi OriginalUpdateBL
1. modify line 68 by switching the listed URL with the following:
2. http://urlblacklist.com/cgi-bin/commercialdownload.pl?type=download&file=bigblacklist
chmod 777 /etc/dansguardian/OriginalUpdateBL
/etc/dansguardian/OriginalUpdateBL
when script is finished if you see any errors.
/etc/init.d/dansguardian restart
if the above script is not creating blacklists directory and creating blacklists file then follow the following:
cd /etc/dansguardian
wget http://urlblacklist.com/cgi-bin/commercialdownload.pl?type=download&file=bigblacklist
tar -xvf bigblacklist.tar.gz
chown -R root:root blacklists
chmod -R 755 blacklists
Webmin and Dansguardian webmin configuration
Login into Webmin(open your web browser and enter the following):
https://192.168.80.1:10000/
Install and configure the Dansguardian Webmin module:
1.Open browser & login as madmin(sudo user) https://192.168.80.1:10000
2.Go to Webmin > Webmin Configuration > Webmin Modules
Select "From ftp or http URL" and paste the link below into the dialog box and click Install Module.
(http://downloads.sourceforge.net/project/dgwebminmodule/dgwebmin-devel/0.7.0beta1b/dgwebmin-0.7.0beta1b.wbm?use_mirror=voxel)
Observe: The following modules have been successfully installed and added to your access control list :
DansGuardian Web Content Filter in /usr/share/webmin/dansguardian (4612 kB) under category Servers
Trouble shooting:
The first time you try to run the dg module, you'll get errors such as:
Warning - DansGuardian binary file not found, maybe you need to update your module config (especially the directory paths). (Expected location: /sbin/dansguardian)
Solution:The problem is that the we are using different directory locations for many of the files. So, look at the Configurable options for DansGuardian Web Content Filter (in the upper left corner of the dg page) - and nearly every path needs to be changed.
For instance, our binary is in /usr/sbin/dansguardian instead of /sbin/dansguardian, so change that.
Confirm the locations for the rest of the files by running
find / -name dansguardian
results may show:
/usr/share/webmin/dansguardian
/usr/share/lintian/overrides/dansguardian
/usr/share/doc/dansguardian
/usr/share/dansguardian
/usr/sbin/dansguardian
/var/log/dansguardian
/etc/webmin/dansguardian
/etc/init.d/dansguardian
/etc/logrotate.d/dansguardian
/etc/dansguardian
When you've finished replacing all of the locations, hit save on the config page and then "stop & restart DG" on the top right of the main DG page.
Then it should work! If not, check your syslog for errors. You should be able to check the status of DG, review logs with a good viewer, and view and edit many of the detailed configurations.
Friday, January 27, 2012
Using Subclipse Behind a Proxy Server
At my day job I sit behind a corporate firewall protecting and caching web traffic (among other things). For the most part it stays out of the way. But sometimes it rears its ugly head and stands firmly in the path of what I am trying to do.
Earlier this week I was trying to look at a cool new general validation system for ColdFusion called Validat, put out by the great guys at Alagad. They don't have a download on the RIAForge site yet, but the files are available via SVN. I loaded up the subclipse plugin into my Eclipse, restarted and began adding the Validat SVN repository. I started getting errors abou the "RA layer request failed" and "svn: PROPFIND request failed on /Validat/trunk", followed by an error about not being able to connect to the SVN server.
I already had Eclipse setup with my proxy settings, so I thought I was doing something wrong or Alagad didn't actually have the subversion repository up-and-available. After going home that night, I tried it from home and wa-la it worked. Stupid proxy server! So the subclipse plugin won't use the Eclipse proxy settings. (Can that be fixed please!). After digging around the subclipse help site and being redirected to the collab.net help, then unproductively searching through the eclipse workspace, plugins, and configuration folders for the settings file, I was finally able to figure out how to set up subclipse to use the proxy server.
In my Windows development environment, I opened the following file: "C:\Documents and Settings\\Application Data\Subversion\servers" in text editor. Near the bottom of that file is a [global] section with http-proxy-host and http-proxy-port settings. I uncommented those two lines, modified them for my corporate proxy server, went back to the SVN Repository view in Eclipse, refreshed the Validat repository and Boom! it worked!
Earlier this week I was trying to look at a cool new general validation system for ColdFusion called Validat, put out by the great guys at Alagad. They don't have a download on the RIAForge site yet, but the files are available via SVN. I loaded up the subclipse plugin into my Eclipse, restarted and began adding the Validat SVN repository. I started getting errors abou the "RA layer request failed" and "svn: PROPFIND request failed on /Validat/trunk", followed by an error about not being able to connect to the SVN server.
I already had Eclipse setup with my proxy settings, so I thought I was doing something wrong or Alagad didn't actually have the subversion repository up-and-available. After going home that night, I tried it from home and wa-la it worked. Stupid proxy server! So the subclipse plugin won't use the Eclipse proxy settings. (Can that be fixed please!). After digging around the subclipse help site and being redirected to the collab.net help, then unproductively searching through the eclipse workspace, plugins, and configuration folders for the settings file, I was finally able to figure out how to set up subclipse to use the proxy server.
In my Windows development environment, I opened the following file: "C:\Documents and Settings\
S M A R T - E X E R C I S E - T I P S & ( B M I )
Be sure to consult your doctor before beginning any exercise program.
Books, videotapes, internet and personal trainers are all great sources of information on exercise program. Make sure the information comes from a credible source such as 'The American College of Sports Medicine' (ACSM) or 'The American Council on Exercise' (ACE).
For every good information resource, there is also a gimmick or fad. A simple rule of thumb is that if it sounds too good to be true, then it probably is. The best route to a happier, healthier life is good old-fashioned work - 20 + minutes per day, 3-5 times per week. Several key considerations will help you determine the best program for you.
FIT ( Frequency, intensity, time) , heart rate, exercise variety and setting goals.
Heart Rate: Your heart rate is your body's speedometer. The best way to gauge your exercise intensity is by measuring your heart rate.
What should my heart rate be?
To understand exercise intensity you must first determine your theoretical maximum heart rate (TMHR) by substracting your age from 220. The lower limit of your heart rate training zone is 55 % of your TMHR; the upper limit is 90 % of TMHR. You should always exercise within these numbers.
Example: for a 30 year old exerciser:
220-30 = 190 TMHR in beats per minutes (BPM)
Lower Limit: 190 * 0.55 = 104.5 BPM
Upper Limit: 190 * 0.90 = 171.0 BPM
This shows that a 30-year-old exerciser's heart rate should be between 104.5 and 171 beats per minutes during a workout.
If your exercise goal is to burn fat and lose weight, you should exercise in the range of 60 % to 70 % of your TMHR. You should also exercise for a longer period of time, at least 30 minutes. This will maximize the calories being burned from fat stores.
If your goal is to improve your cardiovascular level, then you should train at a higher intensity, in the 75 % to 90 % TMHR range. While exercising in this higher intensity range, you will be conditioning your heart and lungs to maximize your overall cardiovascular fitness.
BMI : Body Mass Index
What is BMI?
Body Mass Index (BMI) is a number calculated from a person's weight and height. BMI is a fairly reliable indicator of body fatness for most people. BMI does not measure body fat directly, but research has shown that BMI correlates to direct measures of body fat, such as underwater weighing and dual energy x-ray absorptiometry (DXA).1, 2 BMI can be considered an alternative for direct measures of body fat. Additionally, BMI is an inexpensive and easy-to-perform method of screening for weight categories that may lead to health problems.
How is BMI used?
BMI is used as a screening tool to identify possible weight problems for adults. However, BMI is not a diagnostic tool. For example, a person may have a high BMI. However, to determine if excess weight is a health risk, a healthcare provider would need to perform further assessments. These assessments might include skinfold thickness measurements, evaluations of diet, physical activity, family history, and other appropriate health screenings.
Why CDC use BMI to measure overweight and obesity ?
Calculating BMI is one of the best methods for population assessment of overweight and obesity. Because calculation requires only height and weight, it is inexpensive and easy to use for clinicians and for the general public. The use of BMI allows people to compare their own weight status to that of the general population.
What are some other ways to measure obesity? Why doesn't CDC use those to determine overweight and obesity among the general public?
Other methods to measure body fatness include skinfold thickness measurements (with calipers), underwater weighing, bioelectrical impedance, dual-energy x-ray absorptiometry (DXA), and isotope dilution. However, these methods are not always readily available, and they are either expensive or need highly trained personnel. Furthermore, many of these methods can be difficult to standardize across observers or machines, complicating comparisons across studies and time periods.
How is BMI Calculated and Interpreted?
BMI is calculated the same way for both adults and children. The calculation is based on the following formulas:
 Interpretation of BMI for adults:
Interpretation of BMI for adults:
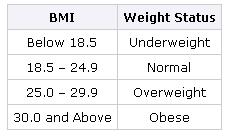
For adults 20 years old and older, BMI is interpreted using standard weight status categories that are the same for all ages and for both men and women. For children and teens, on the other hand, the interpretation of BMI is both age- and sex-specific.
The standard weight status categories associated with BMI ranges for adults are shown in the following table.
Books, videotapes, internet and personal trainers are all great sources of information on exercise program. Make sure the information comes from a credible source such as 'The American College of Sports Medicine' (ACSM) or 'The American Council on Exercise' (ACE).
For every good information resource, there is also a gimmick or fad. A simple rule of thumb is that if it sounds too good to be true, then it probably is. The best route to a happier, healthier life is good old-fashioned work - 20 + minutes per day, 3-5 times per week. Several key considerations will help you determine the best program for you.
FIT ( Frequency, intensity, time) , heart rate, exercise variety and setting goals.
- Frequency: How often you workout. Three to Five time per week is best.
- Intensity: Whatever your exercise goals, you need to exercise at the right intensity level. If you don't exercise hard enough, you won't get the results you want. Exercise too hard and you could experience unnecessary pain and risk injury, leading you to abandon your exercise routine altogether.
- Time: Time is the duration of your workout. To achieve the results you are looking for, it's important that you exercise for 20 minutes. If you are new to exercise, slowly increase the duration of each workout. A great method is to add one minute to each workout until you reach your desired time.
Heart Rate: Your heart rate is your body's speedometer. The best way to gauge your exercise intensity is by measuring your heart rate.
What should my heart rate be?
To understand exercise intensity you must first determine your theoretical maximum heart rate (TMHR) by substracting your age from 220. The lower limit of your heart rate training zone is 55 % of your TMHR; the upper limit is 90 % of TMHR. You should always exercise within these numbers.
Example: for a 30 year old exerciser:
220-30 = 190 TMHR in beats per minutes (BPM)
Lower Limit: 190 * 0.55 = 104.5 BPM
Upper Limit: 190 * 0.90 = 171.0 BPM
This shows that a 30-year-old exerciser's heart rate should be between 104.5 and 171 beats per minutes during a workout.
If your exercise goal is to burn fat and lose weight, you should exercise in the range of 60 % to 70 % of your TMHR. You should also exercise for a longer period of time, at least 30 minutes. This will maximize the calories being burned from fat stores.
If your goal is to improve your cardiovascular level, then you should train at a higher intensity, in the 75 % to 90 % TMHR range. While exercising in this higher intensity range, you will be conditioning your heart and lungs to maximize your overall cardiovascular fitness.
BMI : Body Mass Index
What is BMI?
Body Mass Index (BMI) is a number calculated from a person's weight and height. BMI is a fairly reliable indicator of body fatness for most people. BMI does not measure body fat directly, but research has shown that BMI correlates to direct measures of body fat, such as underwater weighing and dual energy x-ray absorptiometry (DXA).1, 2 BMI can be considered an alternative for direct measures of body fat. Additionally, BMI is an inexpensive and easy-to-perform method of screening for weight categories that may lead to health problems.
How is BMI used?
BMI is used as a screening tool to identify possible weight problems for adults. However, BMI is not a diagnostic tool. For example, a person may have a high BMI. However, to determine if excess weight is a health risk, a healthcare provider would need to perform further assessments. These assessments might include skinfold thickness measurements, evaluations of diet, physical activity, family history, and other appropriate health screenings.
Why CDC use BMI to measure overweight and obesity ?
Calculating BMI is one of the best methods for population assessment of overweight and obesity. Because calculation requires only height and weight, it is inexpensive and easy to use for clinicians and for the general public. The use of BMI allows people to compare their own weight status to that of the general population.
What are some other ways to measure obesity? Why doesn't CDC use those to determine overweight and obesity among the general public?
Other methods to measure body fatness include skinfold thickness measurements (with calipers), underwater weighing, bioelectrical impedance, dual-energy x-ray absorptiometry (DXA), and isotope dilution. However, these methods are not always readily available, and they are either expensive or need highly trained personnel. Furthermore, many of these methods can be difficult to standardize across observers or machines, complicating comparisons across studies and time periods.
How is BMI Calculated and Interpreted?
BMI is calculated the same way for both adults and children. The calculation is based on the following formulas:

For adults 20 years old and older, BMI is interpreted using standard weight status categories that are the same for all ages and for both men and women. For children and teens, on the other hand, the interpretation of BMI is both age- and sex-specific.
The standard weight status categories associated with BMI ranges for adults are shown in the following table.

Useful Links being in America.
- Your access to Free Credit Report - Know Your Rights.
- For Indians - 'Consulate General of India' - San Francisco.
- Best site with all information about your american immigration.
- Tax Filing & Return - IRS
- Get Electronic Filing Pin - IRS Site
- HR Block - Create Your Account
- IRS Free File Tax Filing
- CAR Buying Tips:
- Check Values of CAR on Kelly Blue Book (KBB)
- Check CAR History - CARFAX
- Take the CAR (with permission from CAR seller) to the CAR Brand Dealer, ask them to inspect - they usually charge small price.
- Come up with the price w.r.t. Step #1, Step #2 and Step #3. Reduce your price bit more and bargain with the seller (Seller don't want to go to dealers because they don't want to pay extra money to go through dealers, they prefer to sell to you ;) ).
Sunday, January 22, 2012
Creating the wlfullclient.jar using the WebLogic JarBuilder tool
Creating a wlfullclient.jar for JDK 1.6 client applications
- Change directories to the server/lib directory. $ cd WL_HOME/server/lib
- Use the following command to create wlfullclient.jar in the server/lib directory:$ java -jar wljarbuilder.jar
- You can now copy and bundle the wlfullclient.jar with client applications.
- Add the wlfullclient.jar to the client application’s classpath.
Creating a wlfullclient5.jar for JDK 1.5 client applications
- Change directories to the server/lib directory. $ cd WL_HOME/server/lib
- Use the following command to create wlfullclient.jar in the server/lib directory: $ java -jar wljarbuilder.jar -profile wlfullclient5
- You can now copy and bundle the wlfullclient5.jar with client applications.
- Add the wlfullclient5.jar to the client application’s classpath.
Saturday, January 14, 2012
GIT - GITOSIS & GITWEB - SETUP
Intall Git
After logging into your box, let’s install Git (if not already installed):
Intall python-setuptools
Also install the python-setuptools because we’ll need them (gitosis is written in python):
Download Gitosis
We need to clone the gitosis source locally to install it:
Create Git User:
You need to initially use your public ssh key (id_rsa.pub). If you have one, it will be at $HOME/.ssh/id_rsa.pub and if you have never generated one, you can do so by running the following command (accept the default location and you don’t need to enter a passphrase when prompted):
Sidenote: SSH Port
If you have your sshd daemon running on a different port other than 22 (which is the default, but I highly suggest changing), then you need to use scp like this:
Initialize gitosis-admin repository
On the server, issue the following command to set your public ssh key as the first authorized key of a new gitosis-admin repository:
You have to set the permissions on the post-update git hook of the gitosis-admin repository so that gitosis-admin can add new repository structures when they are added/removed to/from the gitosis.conf file.
Clone gitosis-admin repository
Now we’re going to use Git to administrate this gitosis instance. I think that is pretty ingenius. Let’s clone the gitosis-admin repository locally:
Two most common errors
#1> it is because you have used a port for SSH other than port 22 (the default). To fix this, you need to edit your .ssh/config file and add: "HOST YOUR_SERVER_HOSTNAME" / "PORT YOUR_PORT"
Of course, you need to put in your server hostname and port number (i.e., mydomain.com and 12345)
#2> This has usually hit me because I locked down my /etc/ssh/sshd_config file to only allow in certain users or groups. I have to change the AllowUsers line in my file from: "Allowusers dixitgitscm" to "Allowusers dixitgitscm git" and then restart the ssh daemon:
The local gitosis-admin repository
You now have a local clone of the gitosis-admin repository. The contents are only a conf file and key directory:
~/gitosis-admin(master)>ls
total 8
-rw-r--r-- 1 user staff 1148 May 22 21:31 gitosis/conf
drwxr-xr-x 3 user staff 1148 May 22 21:31 keydir
I like knowing which Git branch I’m currently in. I use the git-ps1 function feature that comes with git-core. If you clone or download the git source: "$ git://git.kernel.org/pub/scm/git/git.git" There is a file in the contrib/completion folder called git-completion.bash:
~/code/git/contrib/completion<span class="o">(</span>master<span class="o">)</span> > ls
total 96
-rwxr-xr-x 1 user staff 44K Apr 14 15:26 git-completion.bash
I copy this file to my $HOME folder as .git-completion.bash and then reference it and the ps1 propt feature in my .bashrc file
<span class="nb">source</span> ~/.git-completion.bash
<span class="nb">export </span><span class="nv">PS1</span><span class="o">=</span><span class="s1">'w$(__git_ps1 "(%s)") > '</span>
And now whenever I cd into a folder that is a Git repository I see something like the following prompt:
~/gitosis-admin<span class="o">(</span>master<span class="o">)</span> >
Notice the (master) notation. That is telling me I’m on the master branch. It’s just easier than issuing a “git branch” command everytime I want to know.
After logging into your box, let’s install Git (if not already installed):
"$ sudo apt-get install git-core"
Press enter or type ‘Y’ and press enter and git will be installed. Type the following to confirm:"$ git --version"
and you’ll see something like: git version 1.6.3.3Intall python-setuptools
Also install the python-setuptools because we’ll need them (gitosis is written in python):
"$apt-get install python-setuptools"
Download Gitosis
We need to clone the gitosis source locally to install it:
"$ mkdir src && cd src"
"~/src $ git clone git://eagain.net/gitosis.git"
Install Gitosis Now let’s install it:"~src $ cd gitosis"
"~/src/gitosis $ python setup.py install"
"result": http://gist.github.com/352769
Gist. Gitosis is now installed. Next steps are to create git user and handle a file permission on a git hook.Create Git User:
"$ sudo adduser --system --shell /bin/bash --gecos --group --disabled-password --home /home/git git"
Use local, public ssh keyYou need to initially use your public ssh key (id_rsa.pub). If you have one, it will be at $HOME/.ssh/id_rsa.pub and if you have never generated one, you can do so by running the following command (accept the default location and you don’t need to enter a passphrase when prompted):
"$ ssh-keygen -t rsa"
Now you need to upload it to the server/slice. I usually use the scp (secure copy command):"$ scp $HOME/.ssh/id_rsa.pub user@192.168.1.1:/tmp/"
This will upload the local id_rsa.pub file to the /tmp/ folder on the server. Why there? So that the git user can use it. How is that possible? The folder has permissions of 777 (drwxrwxrwt) meaning everyone has read and write access to it.Sidenote: SSH Port
If you have your sshd daemon running on a different port other than 22 (which is the default, but I highly suggest changing), then you need to use scp like this:
"$ scp -P 1234 $HOME/.ssh/id_rsa.pub user@192.168.1.1:/tmp/"
I believe the “-P” option must be capitalized.Initialize gitosis-admin repository
On the server, issue the following command to set your public ssh key as the first authorized key of a new gitosis-admin repository:
"$ sudo -H -u git gitosis-init < /tmp/id_rsa.pub"
Change Permissions on post-update hookYou have to set the permissions on the post-update git hook of the gitosis-admin repository so that gitosis-admin can add new repository structures when they are added/removed to/from the gitosis.conf file.
"$ sudo chmod 755 /home/git/repositories/gitosis-admin.git/hooks/post-update"
Note: First round of this post, I didn’t make this change. When I added a new project, it failed because this hook didn’t have the right permissions.Clone gitosis-admin repository
Now we’re going to use Git to administrate this gitosis instance. I think that is pretty ingenius. Let’s clone the gitosis-admin repository locally:
"$ git clone git@YOUR_SERVER_HOSTNAME:gitosis-admin.git"
We are now in the gitosis-admin repository folder locallyTwo most common errors
#1> it is because you have used a port for SSH other than port 22 (the default). To fix this, you need to edit your .ssh/config file and add: "HOST YOUR_SERVER_HOSTNAME" / "PORT YOUR_PORT"
Of course, you need to put in your server hostname and port number (i.e., mydomain.com and 12345)
#2> This has usually hit me because I locked down my /etc/ssh/sshd_config file to only allow in certain users or groups. I have to change the AllowUsers line in my file from: "Allowusers dixitgitscm" to "Allowusers dixitgitscm git" and then restart the ssh daemon:
"$ sudo /etc/init.d/ssh restart"
Now the git user has access to reach my server/slice via ssh.The local gitosis-admin repository
You now have a local clone of the gitosis-admin repository. The contents are only a conf file and key directory:
~/gitosis-admin(master)>ls
total 8
-rw-r--r-- 1 user staff 1148 May 22 21:31 gitosis/conf
drwxr-xr-x 3 user staff 1148 May 22 21:31 keydir
-----------------------------------------------------------------------------------------------
Note: before anyone asks, the (master) notation in my prompt is usage of the __git_ps1I like knowing which Git branch I’m currently in. I use the git-ps1 function feature that comes with git-core. If you clone or download the git source: "$ git://git.kernel.org/pub/scm/git/git.git" There is a file in the contrib/completion folder called git-completion.bash:
~/code/git/contrib/completion<span class="o">(</span>master<span class="o">)</span> > ls
total 96
-rwxr-xr-x 1 user staff 44K Apr 14 15:26 git-completion.bash
I copy this file to my $HOME folder as .git-completion.bash and then reference it and the ps1 propt feature in my .bashrc file
<span class="nb">source</span> ~/.git-completion.bash
<span class="nb">export </span><span class="nv">PS1</span><span class="o">=</span><span class="s1">'w$(__git_ps1 "(%s)") > '</span>
And now whenever I cd into a folder that is a Git repository I see something like the following prompt:
~/gitosis-admin<span class="o">(</span>master<span class="o">)</span> >
Notice the (master) notation. That is telling me I’m on the master branch. It’s just easier than issuing a “git branch” command everytime I want to know.
----------------------------------------------------------------
Add Projects and Contributors
Subscribe to:
Posts (Atom)