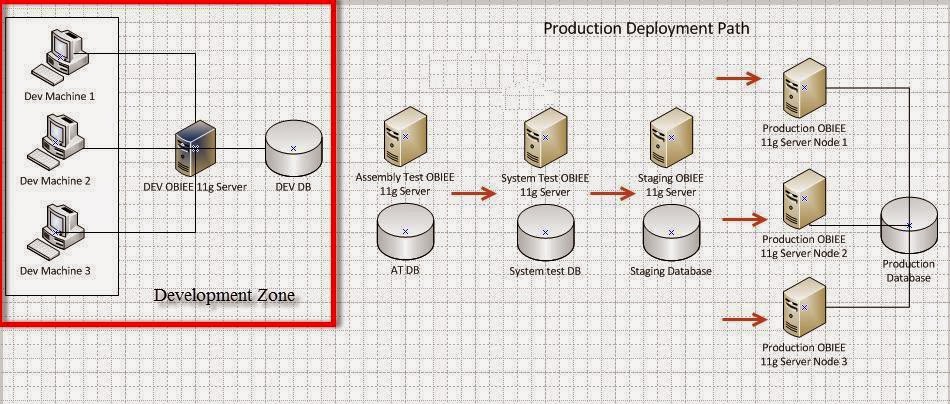
A typical deployment process an OBIEE 11g repository will follow in most production environments resembles the following:

The development zone represents a series of developer machines modifying a repository either by:
Multi User Directory Environment Configuration (MUDE)
Local development machines where each developer migrates their changes to a centralized OBIEE 11g dev/unit test box via a patch-merge process.
We're going to focus on the 'Production Deployment Path' that takes the repository from the Dev/Unit test machine and migrates it through the deployment path from Assembly Test through Production.
This production path is critical because it's at this point where the repository leaves the 'safe haven' of the developer environment and goes through various stages of testing, usually performed by another team. Each testing team will have their own BI Server and database that the repository must connect to for testing.
Usually, the repository remains the same through all environments except for:
Step 1: Generate the XUDML file for the assembly, system, staging and production environments:
We're going to create an eXtensible Universal Database Markup Language (XUDML for short) that contains connection pools specific for each environment. This file is generated by biserverxmlgen and is basically the repository exported to XML. The way to accomplish this in OBIEE 10g was using UDML which has seen been deprecated and is not supported by Oracle - see Oracle Note 1068266.1.
Step 1.1 - Set Variables via bi-init.sh
. /export/obiee/11g/instances/instance1/bifoundation/OracleBIApplication/coreapplication/setup/bi-init.sh
Note the space between the '.' and the '/' . This is required for the i-init.sh script to propagate through all folders
Step 1.2 - Generate XUDML file
Navigate to export/obiee/11g/Oracle_BI1/bifoundation/server/bin/ and run:
biserverxmlgen -R C:\testconnpool\base.rpd -P Admin123 -O c:\testconnpool\test.xml -8
Replace base.rpd with your source RPD - i.e. if you want to generate connection pool information for assembly test, base.rpd should represent your assembly test repository.
If fail to set your session variables will you encounter the following error:
"libnqsclusterapi64.so: open failed: No Such file or directory"

If you are successful, your output should be as follows:

Step 1.3 Remove inapplicable entries
For connection pool migrations, your script should only include:
Step 2: Apply XUDML file to base repository
Let's say you have an assembly test repository and a system test XUDML file. The biserverxmlexec.sh script will take your assembly test repository, system test XUDML file and generate a 'system test repository' using the following command located in export/obiee/11g/Oracle_BI1/bifoundation/server/bin/
biserverxmlexec -I input_file_pathname [-B base_repository_pathname] [-P password] -O output_repository_pathname
Where:
input_file_pathname is the name and location of the XML input file you want to execute base_repository_pathname is the existing repository file you want to modify using the XML input file (optional). Do not specify this argument if you want to generate a new repository file from the XML input file. password is the repository password.
If you specified a base repository, enter the repository password for the base repository. If you did not specify a base repository, enter the password you want to use for the new repository.
The password argument is optional. If you do not provide a password argument, you are prompted to enter a password when you run the command. To minimize the risk of security breaches, Oracle recommends that you do not provide a password argument either on the command line or in scripts. Note that the password argument is supported for backward compatibility only, and will be removed in a future release.
output_repository_pathname is the name and location of the RPD output file you want to generate.
Example:
biserverxmlexec -I testxudml.txt -B rp1.rpd -O rp2.rpd
Give password: my_rpd_password
You now have a system test repository that you can upload to your applicable environment.
Step 3: Upload Repository to BI Server via WLST
Many web sites show how to upload the repository via the FMW Enterprise Manager, but that is generally alot slower and not as efficient as scripting it.
connect('user','pass','server')
user = ''
password = ''
host = ''
port = ''
rpdpath = '/path/path2/repository.rpd'
rpdPassword = ''
# Be sure we are in the root
cd("..\..")
print(host + ": Connecting to Domain ...")
try:
domainCustom()
except:
print(host + ": Already in domainCustom")
print(host + ": Go to biee admin domain")
cd("oracle.biee.admin")
# go to the server configuration
print(host + ": Go to BIDomain.BIInstance.ServerConfiguration MBean")
cd ('oracle.biee.admin:type=BIDomain,group=Service')
biinstances = get('BIInstances')
biinstance = biinstances[0]
# Lock the System
print(host + ": Calling lock ...")
cd("..")
cd("oracle.biee.admin:type=BIDomain,group=Service")
objs = jarray.array([], java.lang.Object)
strs = jarray.array([], java.lang.String)
try:
invoke("lock", objs, strs)
except:
print(host + ": System already locked")
cd("..")
# Upload the RPD
cd (biinstance.toString())
print(host + ": Uploading RPD")
biserver = get('ServerConfiguration')
cd('..')
cd(biserver.toString())
ls()
argtypes = jarray.array(['java.lang.String','java.lang.String'],java.lang.String)
argvalues = jarray.array([rpdpath,rpdPassword],java.lang.Object)
invoke('uploadRepository',argvalues,argtypes)
# Commit the system
print(host + ": Commiting Changes")
cd('..')
cd('oracle.biee.admin:type=BIDomain,group=Service')
objs = jarray.array([],java.lang.Object)
strs = jarray.array([],java.lang.String)
invoke('commit',objs,strs)
# Restart the system
print(host + ": Restarting OBIEE processes")
cd("..\..")
cd("oracle.biee.admin")
cd("oracle.biee.admin:type=BIDomain.BIInstance,biInstance=coreapplication,group=Service")
print(host + ": Stopping the BI instance")
params = jarray.array([], java.lang.Object)
signs = jarray.array([], java.lang.String)
invoke("stop", params, signs)
BIServiceStatus = get("ServiceStatus")
print(host + ": BI ServiceStatus " + BIServiceStatus)
print(host + ": Starting the BI instance")
params = jarray.array([], java.lang.Object)
signs = jarray.array([], java.lang.String)
invoke("start", params, signs)
BIServerStatus = get("ServiceStatus")
print(host + ": BI ServerStatus " + BIServerStatus)
The aforementioned code works on scaled out (clustered) environments since there is only one active admin server. The code will connect to the active admin server located in your first node, and WLST will propagate changes to each node. You can validate this by navigating to the local repository folder of each node.
To run the script, load wlst located at :
/export/obiee/11g/oracle_common/common/bin/wlst.sh
and perform the execfile command as follows:
execfile(‘/path/path1/path2/uploadRPD.py’)
In conclusion, the entire repository deployment process can be executed by the following two scripts:
biserverxmlexec (provided by Oracle)
uploadRpd.py (see above)
Reference: Fusion Middleware Integrator's Guide for Oracle Business Intelligence Enterprise Edition
The development zone represents a series of developer machines modifying a repository either by:
Multi User Directory Environment Configuration (MUDE)
Local development machines where each developer migrates their changes to a centralized OBIEE 11g dev/unit test box via a patch-merge process.
We're going to focus on the 'Production Deployment Path' that takes the repository from the Dev/Unit test machine and migrates it through the deployment path from Assembly Test through Production.
This production path is critical because it's at this point where the repository leaves the 'safe haven' of the developer environment and goes through various stages of testing, usually performed by another team. Each testing team will have their own BI Server and database that the repository must connect to for testing.
Usually, the repository remains the same through all environments except for:
- Connection Pools
- Environment specific server variables
- Generating an XUDML file that connections connection pool information.
- Generating a new system test repository by applying the System test XUDML to the assembly test repository.
- Using WLST to upload the RPD to the specified environment.
Step 1: Generate the XUDML file for the assembly, system, staging and production environments:
We're going to create an eXtensible Universal Database Markup Language (XUDML for short) that contains connection pools specific for each environment. This file is generated by biserverxmlgen and is basically the repository exported to XML. The way to accomplish this in OBIEE 10g was using UDML which has seen been deprecated and is not supported by Oracle - see Oracle Note 1068266.1.
Step 1.1 - Set Variables via bi-init.sh
. /export/obiee/11g/instances/instance1/bifoundation/OracleBIApplication/coreapplication/setup/bi-init.sh
Note the space between the '.' and the '/' . This is required for the i-init.sh script to propagate through all folders
Step 1.2 - Generate XUDML file
Navigate to export/obiee/11g/Oracle_BI1/bifoundation/server/bin/ and run:
biserverxmlgen -R C:\testconnpool\base.rpd -P Admin123 -O c:\testconnpool\test.xml -8
Replace base.rpd with your source RPD - i.e. if you want to generate connection pool information for assembly test, base.rpd should represent your assembly test repository.
- -O generates the output XML file
- -8 represents the UTF-8 formatting for the XML file
- -P represents the password of the base repository
If fail to set your session variables will you encounter the following error:
"libnqsclusterapi64.so: open failed: No Such file or directory"

If you are successful, your output should be as follows:

Step 1.3 Remove inapplicable entries
For connection pool migrations, your script should only include:
<?xml version="1.0" encoding="UTF-8" ?>
<Repository xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<DECLARE>
<Connection Pool ......>
</ConnectionPool>
</DECLARE>
</Repository>
You will only need to re-generate this file if you change your connection pool information. This XUDML file will be used to update connection pools of your target environment.
Step 2: Apply XUDML file to base repository
Let's say you have an assembly test repository and a system test XUDML file. The biserverxmlexec.sh script will take your assembly test repository, system test XUDML file and generate a 'system test repository' using the following command located in export/obiee/11g/Oracle_BI1/bifoundation/server/bin/
biserverxmlexec -I input_file_pathname [-B base_repository_pathname] [-P password] -O output_repository_pathname
Where:
input_file_pathname is the name and location of the XML input file you want to execute base_repository_pathname is the existing repository file you want to modify using the XML input file (optional). Do not specify this argument if you want to generate a new repository file from the XML input file. password is the repository password.
If you specified a base repository, enter the repository password for the base repository. If you did not specify a base repository, enter the password you want to use for the new repository.
The password argument is optional. If you do not provide a password argument, you are prompted to enter a password when you run the command. To minimize the risk of security breaches, Oracle recommends that you do not provide a password argument either on the command line or in scripts. Note that the password argument is supported for backward compatibility only, and will be removed in a future release.
output_repository_pathname is the name and location of the RPD output file you want to generate.
Example:
biserverxmlexec -I testxudml.txt -B rp1.rpd -O rp2.rpd
Give password: my_rpd_password
You now have a system test repository that you can upload to your applicable environment.
Step 3: Upload Repository to BI Server via WLST
Many web sites show how to upload the repository via the FMW Enterprise Manager, but that is generally alot slower and not as efficient as scripting it.
The uploadRPD.py script below performs five tasks:
- Connects to WLST
- Locks the System
- Uploads the RPD
- Commits Changes
- Restarts BI Services
connect('user','pass','server')
user = ''
password = ''
host = ''
port = ''
rpdpath = '/path/path2/repository.rpd'
rpdPassword = ''
# Be sure we are in the root
cd("..\..")
print(host + ": Connecting to Domain ...")
try:
domainCustom()
except:
print(host + ": Already in domainCustom")
print(host + ": Go to biee admin domain")
cd("oracle.biee.admin")
# go to the server configuration
print(host + ": Go to BIDomain.BIInstance.ServerConfiguration MBean")
cd ('oracle.biee.admin:type=BIDomain,group=Service')
biinstances = get('BIInstances')
biinstance = biinstances[0]
# Lock the System
print(host + ": Calling lock ...")
cd("..")
cd("oracle.biee.admin:type=BIDomain,group=Service")
objs = jarray.array([], java.lang.Object)
strs = jarray.array([], java.lang.String)
try:
invoke("lock", objs, strs)
except:
print(host + ": System already locked")
cd("..")
# Upload the RPD
cd (biinstance.toString())
print(host + ": Uploading RPD")
biserver = get('ServerConfiguration')
cd('..')
cd(biserver.toString())
ls()
argtypes = jarray.array(['java.lang.String','java.lang.String'],java.lang.String)
argvalues = jarray.array([rpdpath,rpdPassword],java.lang.Object)
invoke('uploadRepository',argvalues,argtypes)
# Commit the system
print(host + ": Commiting Changes")
cd('..')
cd('oracle.biee.admin:type=BIDomain,group=Service')
objs = jarray.array([],java.lang.Object)
strs = jarray.array([],java.lang.String)
invoke('commit',objs,strs)
# Restart the system
print(host + ": Restarting OBIEE processes")
cd("..\..")
cd("oracle.biee.admin")
cd("oracle.biee.admin:type=BIDomain.BIInstance,biInstance=coreapplication,group=Service")
print(host + ": Stopping the BI instance")
params = jarray.array([], java.lang.Object)
signs = jarray.array([], java.lang.String)
invoke("stop", params, signs)
BIServiceStatus = get("ServiceStatus")
print(host + ": BI ServiceStatus " + BIServiceStatus)
print(host + ": Starting the BI instance")
params = jarray.array([], java.lang.Object)
signs = jarray.array([], java.lang.String)
invoke("start", params, signs)
BIServerStatus = get("ServiceStatus")
print(host + ": BI ServerStatus " + BIServerStatus)
The aforementioned code works on scaled out (clustered) environments since there is only one active admin server. The code will connect to the active admin server located in your first node, and WLST will propagate changes to each node. You can validate this by navigating to the local repository folder of each node.
To run the script, load wlst located at :
/export/obiee/11g/oracle_common/common/bin/wlst.sh
and perform the execfile command as follows:
execfile(‘/path/path1/path2/uploadRPD.py’)
In conclusion, the entire repository deployment process can be executed by the following two scripts:
biserverxmlexec (provided by Oracle)
uploadRpd.py (see above)
Reference: Fusion Middleware Integrator's Guide for Oracle Business Intelligence Enterprise Edition